Monorepo
Monorepo 是一种代码组织方式,将所有有关项目都放在同一个 repo 中。与 Multirepo 相对,Multirepo 中各个项目各自拥有各自的 repo。
据说,Google 所有的代码都维护在一个「repo」里,这也可以理解成「monorepo」。
Why monorepo
在初期开发的时候,基本上就是一个模块开一个 repo 的,基本比较流畅。尤其是我使用了create-react-app这一类的东西,会直接帮你建好一个新的 git repo。之后也是一个 repo 一个 repo 地测试和打包镜像,如果后一个 repo 依赖前一个 repo 提供的服务,也是通过起 Docker 容器的方式满足后一个 repo 的依赖来调试。
整个项目基本完成以后,也就暂时放在那了(即使还有不少已知 Bug)。之后想找个地方记一下有哪些 Bug,当然首先是想到了 GitHub 的 issues 模块,结果一看就傻眼了,很纠结有些 Bug 到底应该提到哪里,如果太散乱也不好管理。这时就种草了 monorepo。
另外其实这个项目目前就我一个人搞,把 repo 搞的到处都是也不方便自己浏览和维护。而且名字类似的一长列 repo 占据了我的 GitHub 首页左边栏,也有碍观瞻。总之,最后就下定决心要把这些 repo 迁移到一个 monorepo 了。
Tomono
tomono 是一个「Multi- To Mono-repository」的迁移工具。这是一个 shell 脚本,只有 100 来行。使用也比较方便,简单来说,你给它一个 repo list,它会自动帮你梳理 git log/branch/tags,合理地将多个 repo 合并成一个 repo。具体的代码和用法可以直接在 GitHub 参考。个人的用法比较粗暴,直接一个文件夹一个 repo 放在根目录下,没有像 lerna 那样再套一层 packages 路径。其实由于这个项目没有 npm 模块需要发布,所以没有必要使用 lerna 等 monorepo 管理工具。
由于 tomono 的过程中需要做git fetch,而我这些 repo 中其中有一个和环境配置有关,放了很多编译产物,比较大,于是先从 list 里去掉了。tomono 很顺利地帮我合并了剩下的 6 个 repo。由于这些 multirepo 我之后不再需要了,因此要不然 delete,要不然 archive 了。但 tomono 自动会在 remote 里添加这些旧的 repo,因此需要手动git remote remove掉。当然,还要把最后那个 repo 手动mv进来。tomono 不会处理你的 LICENCE 和 .gitignore,可以自行拿出来或者合并一波。
After
由于多个 repo 合并成了一个,有些问题之前影响不大,现在也暴露了出来。最典型的就是 GitHub 页面上显示的 Languages 比例直接歪了。本来这个项目应该是一个 Python 和 JavaScript 再加上一些 C 语言的项目,结果因为 C 语言那边放了一个argparse3依赖库,直接就以将近 50% 的比例当选了这个项目的代表语言。此外,那边的编译产物的一堆 html 格式的文档和脚本,也占了一大片山头。
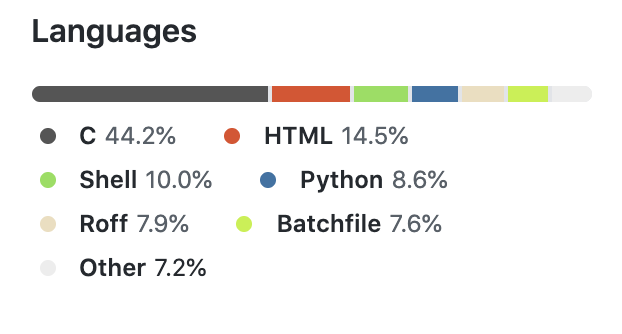
这时候就需要在根目录建一个 .gitattributes 文件,对一些不应该计入语言统计的文件设置linguist-vendored=true参数,如下
1 | argtable3.* linguist-vendored=true |
这样就科学多了。
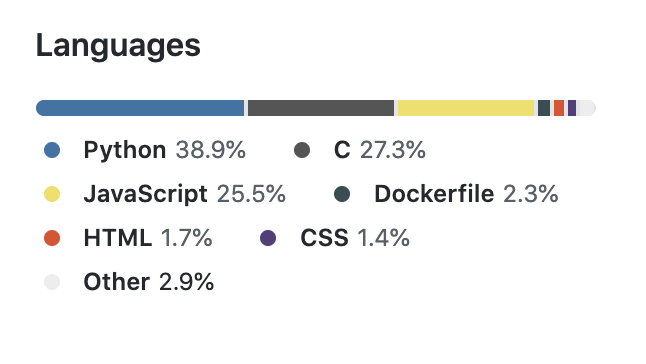
CI/CD
CI/CD 指的是持续集成/部署。一个很 DevOps 的概念。主要是关于代码写完之后一些自动化的事情,例如编译构建镜像,以及测试、发布等。
repo 组织形式的变更,也伴随着 CI/CD 方式的变更。相对语言统计什么的来说,这是个比较大的问题。
本来这个项目的 7 个仓库,其中 5 个是需要 build 出镜像的,其中 2 个对另 1 个编译出的镜像产物有依赖。还有 2 个仓库,一个用来放些部署配置,一个是端到端自动化测试。
之前是在阿里云的镜像中心管理的,为了docker pull速度相对可以接受一些。具体做法是每个 repo 开一个 image,master 分支有变更会触发 latest tag 的 image 构建。显然这在 monorepo 的场景下不再适用。
时过境迁,GitHub 也推出了看起来可用的 GitHub Actions,可以用 yaml 文件自定义 workflow 来做 CI/CD。有了 workflow,其实可以做到更多事情,例如构建完了部署一把,然后跑自动化测试。这在有机器人提 vulnerability 相关的 PR 的时候会非常有用,可以直接在页面上看到依赖版本变更有没有导致测试失败。显然之前 multirepo 的组织方式是没法做的。当然这和我这些仓库的拆分以及没写单元测试有关系。
例如,如下是一个示例的 Docker 镜像构建的 workflow yaml,放在.github/workflows路径下
1 | name: Docker Image CI |
首先我们需要知道怎样的修改触发怎样的构建。第一步,构建镜像并 push 需要登录 Docker Hub,而为了密码不泄露,可以使用 GitHub 的 Secrets 功能,在里面增加对应的用户名和密码变量,并在 yaml 文件中使用。
对于 monorepo 的情况,我们需要根据哪些文件有改动来决定如何构建。GitHub 官方提供了 workflow 级别的这个 feature,根据有改动的路径,我们决定不做哪些构建、做哪些构建。看起来没什么问题,但在 workflow 级别做这个事情还不够灵活。例如,不能满足构建镜像有依赖的情况。第三方 action dorny/paths-filter 则一定程度上增加了 path 检查的灵活性。它在 steps 级别,利用 filter 和 if 的功能使得一些操作的执行是有条件的。这样结合 steps 的串行执行我们可以处理镜像构建时 A、B 依赖 C 的情况。不过也有个缺点, A 和 B 的构建这样就不能并行了。
1 | name: Pipeline |
自动化测试则需要另一个 workflow。测试用例使用了自动化框架 TestCafe,其官方文档提供了一个 GitHub Action,用法如下。
1 | name: End-to-End Tests |
当然,在运行测试前需要先部署,这部分就比较 trick 了,首先依然是按照上面的方法筛选变更的 path,之后由于部署时在docker-compose.yaml用到的镜像名是写死的,因此 workflow 中的镜像构建也需要使用相同的镜像名。这样可以做到本地构建过时先使用本地的镜像,本地没有时从 Docker Hub 拉取。
Which is best
相比 multirepo,虽然解决了依赖混乱和代码零散等问题,monorepo 也并非完美无缺的。比如导致了 repo 的体积非常大(尤其是有大文件的被合并入 monorepo),而每次构建都需要全都拉取下来,拖慢了构建速度。以及在 CI/CD 时需要一些逻辑处理。
另外,虽说 monorepo 里应该放所有相关项目,但有的时候一些相关项目可以作为外部项目的依赖。这个时候也可以考虑拆出去,是有道理的。比如前文提到的 fetch 不下来的那个 repo,其实也可以给另外一个系统当基础镜像用,所以现在又在考虑是不是还是再拆出去比较好。当然还是需要一些权衡的,例如拆出去了以后 monorepo 里的依赖如何自动更新。
所以,事实上并没有最好的代码组织方式,无论是 multirepo 还是 monorepo,都各有优缺点。要根据具体的场景,决定是单独开一个新的 repo,还是写在已有的 monorepo 里。